파이썬으로 HWP 파일 열어서 텍스트로 변환하기
HWP 파일을 Python 으로 열어서 정보를 확인하고, 본문을 텍스트로 변환하는 코드를 작성해보려고 합니다. 한글과컴퓨터에서 공개한 규격 문서를 참고했습니다.
첫번째 블로그 포스트에서 언급한 것처럼, HWP 파일은 마이크로소프트에서 개발한 CFB(Compound File Binary File Format)으로 구성되어 있습니다. 이 형식은 파일시스템처럼 여러 바이너리 데이터를 담을 수 있도록 되어 있는 형식입니다.
그러니까 파일의 맨 앞 헤더만 봐서는 HWP 파일인지 확인할 수 없습니다. 먼저 CFB 파일인지 확인한 다음 CFB 를 파싱해서 HWP 헤더가 있는지 확인해야 합니다. Python 으로 CFB 형식의 파일을 분석하기 위해서 많이 쓰는 라이브러리인 olefile 를 먼저 설치해보죠.
pip install olefile
그리고 먼저 파일이 CFB 파일인지 확인합니다(CFB 파일 == OLE 파일).
if not olefile.isOleFile(file_path):
print(f"'{file_path}' 는 OLE 파일이 아닙니다. 종료합니다.")
exit(1)
그 다음에는 파일을 열어서 그 안에 담겨있는 스트림들의 목록을 가져옵니다.
with olefile.OleFileIO(file_path) as ole:
stream_list = ole.listdir()
print("스트림 목록:")
for entry in stream_list:
print("- " + "/".join(entry)) # entry 는 스토리지/스트림의 리스트로 되어있습니다. 간단하게 슬래시(/)를 붙여서 표시합니다.
규격 문서에는 다음과 같은 스트림들이 있다고 명시되어있습니다.
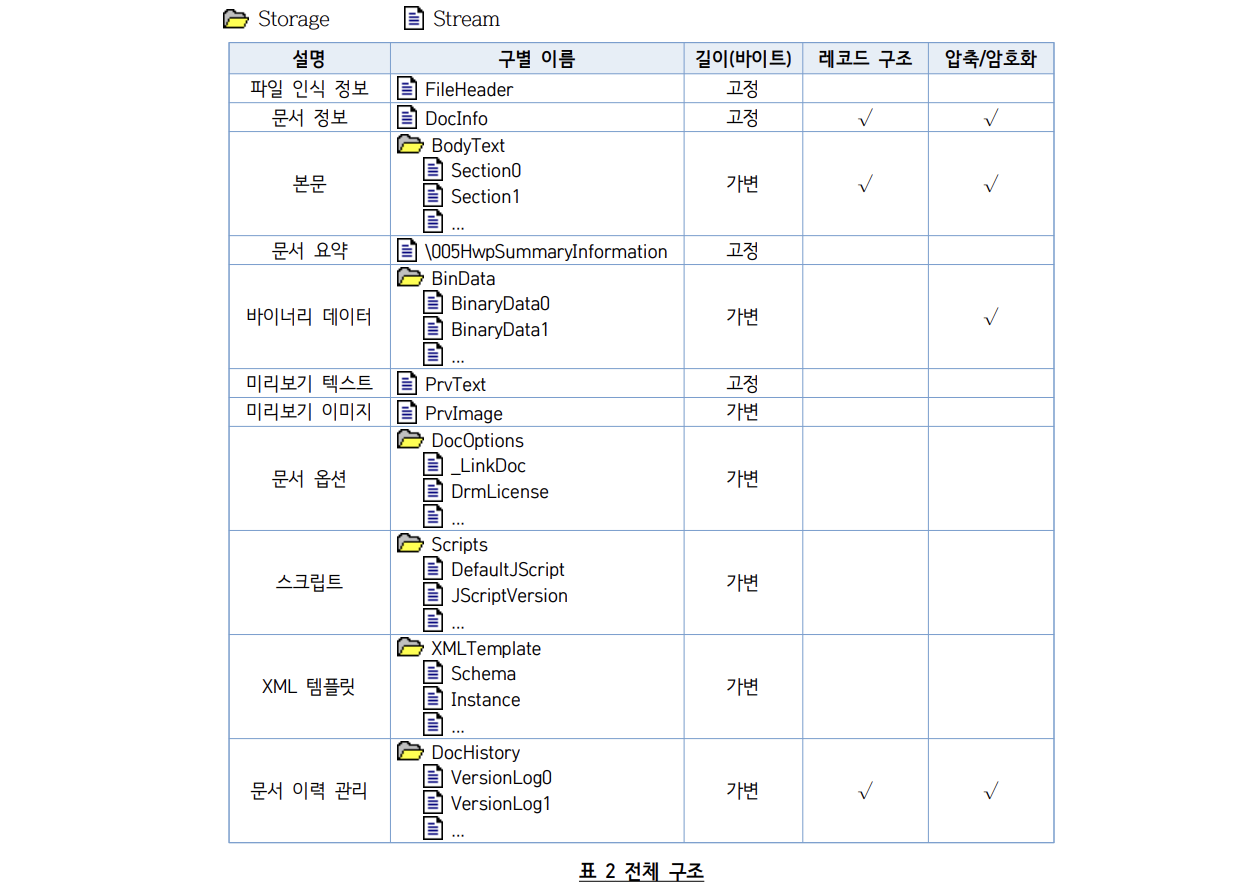
이 중에서 FileHeader 스트림을 보면 HWP 파일인지 확인할 수 있습니다. 그리고 파일이 압축되어있는지, 암호가 설정되어있는지 처럼 중요한 문서의 속성들도 포함하고 있습니다.
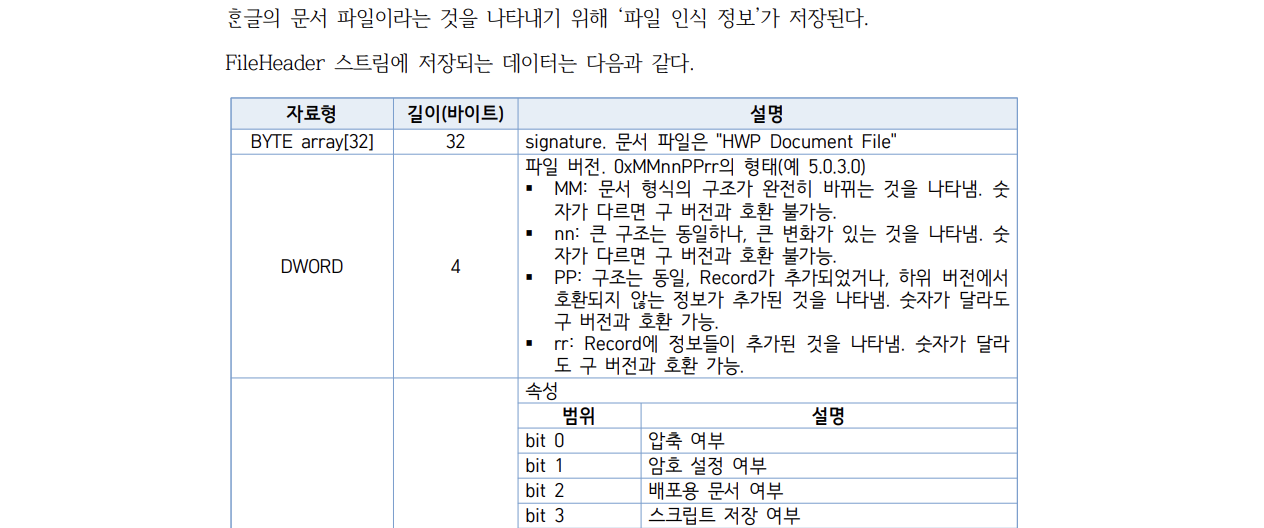
일단 HWP 파일이 맞는지부터 확인해야겠죠.
HWP_HEADER = (
b"HWP Document File\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00" # 32 바이트
)
with ole.openstream(target_stream_path) as stream:
data = stream.read()
header = data[: len(HWP_HEADER)]
if header != HWP_HEADER:
print("HWP 파일이 아닙니다. 종료합니다.")
exit(1)
그 다음에는 HWP 버전을 확인해봅시다.
version_stream = data[32:36] # 32바이트가 헤더 이후의 4바이트를 읽어온다
version_r = int.from_bytes(version_stream[0:1])
version_p = int.from_bytes(version_stream[1:2])
version_n = int.from_bytes(version_stream[2:3]) # 마이너 버전
version_m = int.from_bytes(version_stream[3:4]) # 메이저 버전
version_str = f"{version_m}.{version_n}.{version_p}.{version_r}"
print(version_str)
버전은 다음과 같은 의미를 가지고 있다고 합니다:
- 0xMMnnPPrr의 형태(예 5.0.3.0)
- MM: 문서 형식의 구조가 완전히 바뀌는 것을 나타냄. 숫자가 다르면 구 버전과 호환 불가능.
- nn: 큰 구조는 동일하나, 큰 변화가 있는 것을 나타냄. 숫자가 다르면 구 버전과 호환 불가능.
- PP: 구조는 동일, Record가 추가되었거나, 하위 버전에서 호환되지 않는 정보가 추가된 것을 나타냄. 숫자가 달라도 구 버전과 호환 가능.
- rr: Record에 정보들이 추가된 것을 나타냄. 숫자가 달라도 구 버전과 호환 가능.
그 다음에는 파일의 속성을 확인할 차례입니다.
props_stream = data[36:40] # 버전 다음 4바이트를 읽어온다
props = int.from_bytes(props_stream, byteorder="little") # 4바이트를 32비트 정수형으로 바꾼다.
props_zip = bool((props >> 0) & 1) # 첫번째 비트
props_password = bool((props >> 1) & 1) # 두번째 비트
print(f"압축: {props_zip}, 비밀번호: {props_password}")
int.from_bytes 의 옵션으로 byteorder 는 little 로 지정하고 있는데요, 이 부분도 규격에서 Little Endian 으로 정의되어 있는 부분입니다.
압축이 되어있다면 나중에 본문을 열 때 압축을 풀어줘야 합니다. 이제 본문을 열어보죠. 스토리지가 BodyText 이면 본문입니다.
for entry in stream_list:
if entry[0] == "BodyText":
target_stream_path = "/".join(entry)
with ole.openstream(target_stream_path) as stream:
data = stream.read()
if props_zip: # 압축되어있는 경우
data = zlib.decompress(data, -15)
zlib 으로 압축을 풀 때 -15 를 지정하는 부분은 이 블로그 포스트를 참고하세요.
각각의 data 는 데이터 레코드 구조로 되어있습니다. 첫번째 4바이트에 어떤 데이터인지, 길이가 어디까지인지 명시하고 있는 방식입니다.

규격대로 레코드 헤더를 파싱하는 함수를 만들어보죠.
def extract_record(record_stream: bytes):
dword = int.from_bytes(record_stream, byteorder="little")
tag_id = (dword >> 0) & 0x3FF # 하위 10비트 (0b0011_1111_1111)
level = (dword >> 10) & 0x3FF # 다음 10비트 (0b0011_1111_1111)
size = (dword >> 20) & 0xFFF # 다음 12비트 (0b1111_1111_1111)
return tag_id, level, size
다음 부분에서 본문의 실제 텍스트가 저장되는 Tag ID 가 뭔지 확인할 수 있습니다.
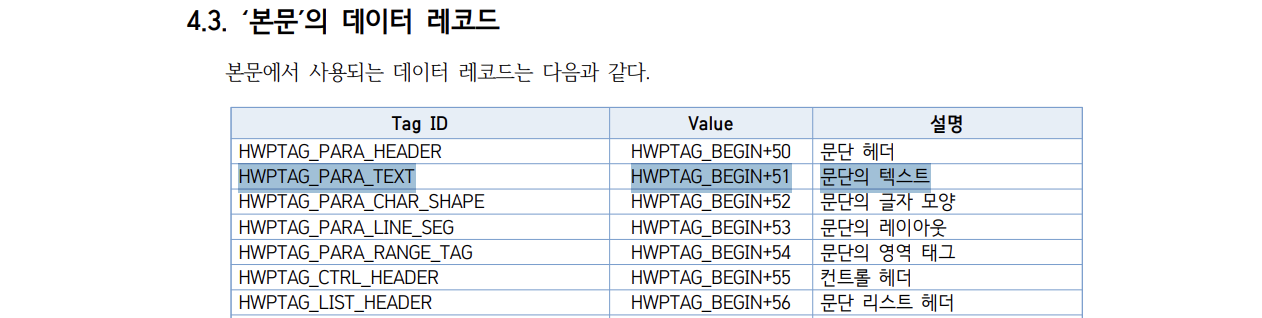
이제 파일을 순차적으로 읽으면서 '문단의 텍스트' 만 가져와봅시다.
HWPTAG_BEGIN = 0x010 # 규격에 명시, 0x00F 까지는 특별한 용도로 예약됨
HWPTAG_PARA_TEXT = HWPTAG_BEGIN + 51 # HWPTAG_BEGIN 이 16 이므로 HWPTAG_PARA_TEXT 는 67
pos = 0
while pos < len(data):
record_stream = data[pos : pos + 4]
tag_id, level, size = extract_record(record_stream)
pos += 4 # 헤더를 읽었으니 현재 위치를 데이터로 이동
if tag_id == HWPTAG_PARA_TEXT:
para_stream = data[pos : pos + size]
para_stream = remove_ctrl_char(para_stream) # 제어 문자는 삭제해야 한다
para_text = para_stream.decode("utf-16")
print(para_text)
pos += size
이제 거의 다 됐습니다. 그냥 본문을 읽어와서 utf-16 으로 변환하면 한자나 특수문자들이 표시됩니다. remove_ctrl_char() 를 구현해서 이 제어 문자들을 삭제해보죠.
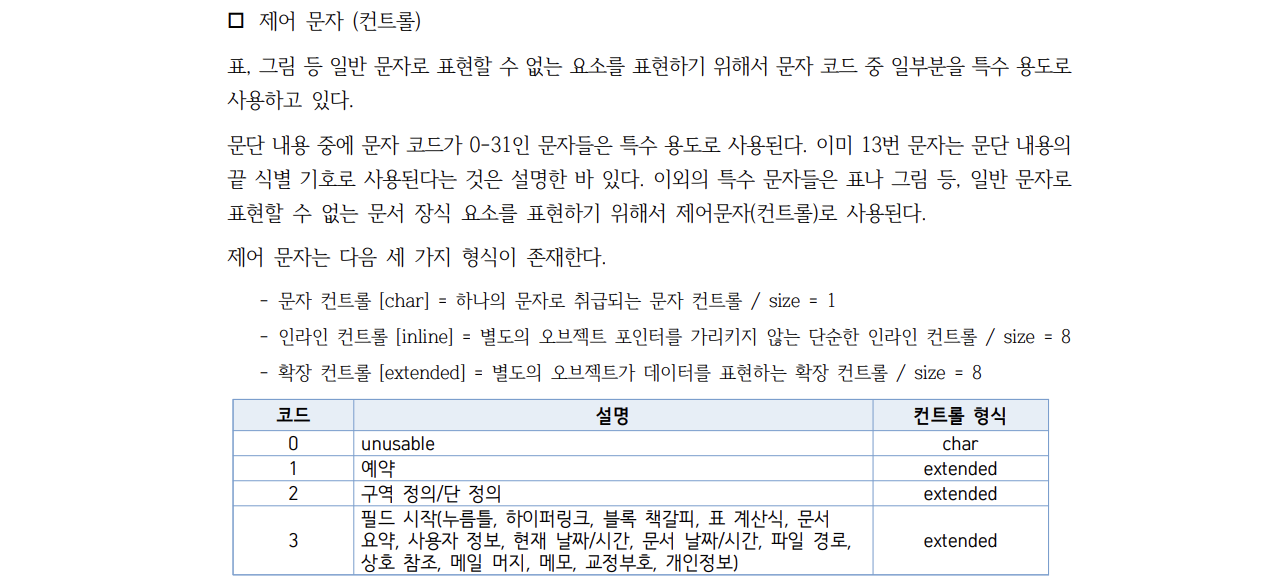
제어 문자는 위와 같이 정의되어있습니다. 2바이트 단위로 읽었을때 31까지는 모두 제어 문자이고, 이 중 char 형식인 것들은 2바이트, 다른 것들은 16바이트입니다.
CHAR_CTRL = [0, 10, 13] + list(range(24, 32)) # char 형식인 제어 문자들의 목록
def remove_ctrl_char(para_stream: bytes):
out = b""
pos = 0
while pos < len(para_stream):
wchar_stream = para_stream[pos : pos + 2]
wchar = int.from_bytes(wchar_stream, "little") # 실제로는 두번째 바이트는 0 이고 첫번째 바이트만 확인
if wchar < 32:
if wchar in CHAR_CTRL:
# 한줄 끝(10) 과 문단 끝(13)은 따로 처리 필요
pos += 2
else:
# 8개의 DWORD 중 마지막은 시작 제어 문자와 동일한지 확인 필요
pos += 16
else:
out += wchar_stream
pos += 2
return out
완료입니다! 복잡한 문서는 물론 부족하지만 텍스트가 제대로 추출되는 것을 볼 수 있습니다.