How to Open HWP Files and Convert Them to Text with Python
I'm going to write some Python code to open an HWP file, check its information, and convert the body to text. I referenced the official specification document released by Hancom.
As mentioned in the first blog post, HWP files are structured using the Compound File Binary File Format (CFB), developed by Microsoft. This format is like a file system, capable of containing multiple binary data streams.
This means you can't identify an HWP file just by looking at the file's initial header. You first need to confirm it's a CFB file, then parse the CFB to check for the HWP header. Let's start by installing olefile, a popular Python library for analyzing CFB files.
pip install olefile
First, let's check if the file is a CFB file (CFB file == OLE file).
if not olefile.isOleFile(file_path):
print(f"'{file_path}' is not an OLE file. Exiting.")
exit(1)
Next, we open the file and get a list of the streams it contains.
with olefile.OleFileIO(file_path) as ole:
stream_list = ole.listdir()
print("Stream List:")
for entry in stream_list:
# entry is a list of storages/streams. We'll join them with a slash (/) for simple display.
print("- " + "/".join(entry))
The specification document states that the following streams exist:
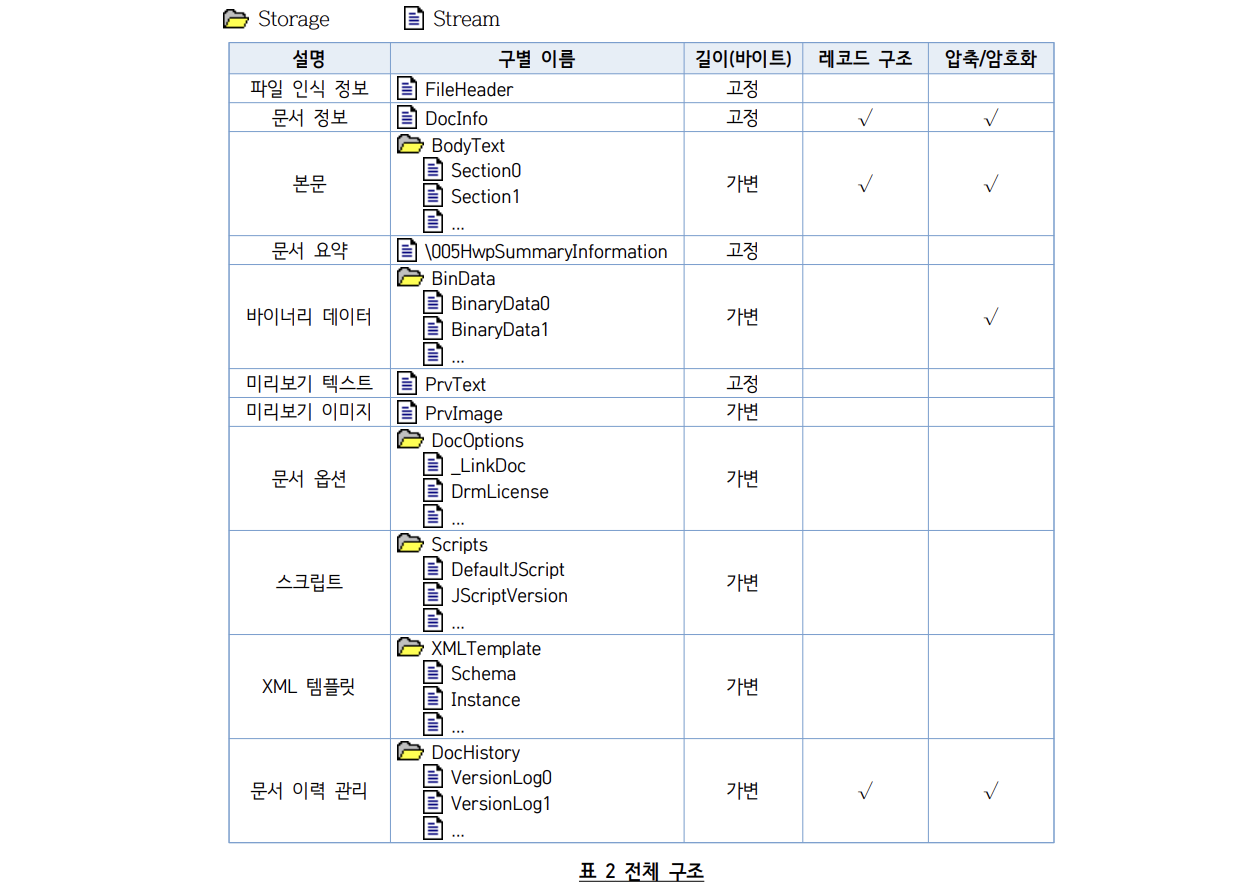
Among these, you can check the FileHeader stream to confirm if it's an HWP file. It also contains important document properties, such as whether the file is compressed or password-protected.
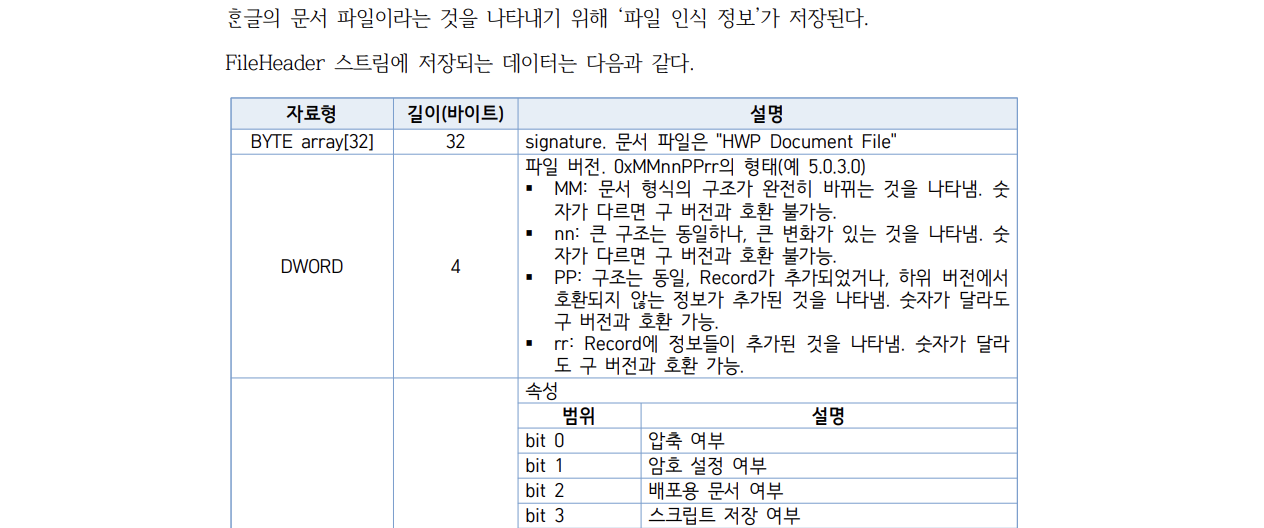
First, let's verify that it's indeed an HWP file.
HWP_HEADER = (
b"HWP Document File\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00" # 32 bytes
)
with ole.openstream(target_stream_path) as stream:
data = stream.read()
header = data[: len(HWP_HEADER)]
if header != HWP_HEADER:
print("Not an HWP file. Exiting.")
exit(1)
Next, let's check the HWP version.
version_stream = data[32:36] # Read the 4 bytes after the 32-byte header
version_r = int.from_bytes(version_stream[0:1])
version_p = int.from_bytes(version_stream[1:2])
version_n = int.from_bytes(version_stream[2:3]) # Minor version
version_m = int.from_bytes(version_stream[3:4]) # Major version
version_str = f"{version_m}.{version_n}.{version_p}.{version_r}"
print(version_str)
The version has the following meaning:
- Format 0xMMnnPPrr (e.g., 5.0.3.0) |
- MM: Indicates a complete change in the document format's structure. Different numbers are not backward compatible.
- nn: Indicates a major change while the main structure remains the same. Different numbers are not backward compatible.
- PP: Indicates the structure is the same, but new records or non-backward compatible information has been added. It is backward compatible with older versions.
- rr: Indicates that new information has been added to records. It is backward compatible with older versions.
Now it's time to check the file's properties.
props_stream = data[36:40] # Read the 4 bytes after the version
props = int.from_bytes(props_stream, byteorder="little") # Convert the 4 bytes to a 32-bit integer
props_zip = bool((props >> 0) & 1) # First bit
props_password = bool((props >> 1) & 1) # Second bit
print(f"Compressed: {props_zip}, Password-Protected: {props_password}")
The byteorder option for int.from_bytes is set to little, as the specification defines it as Little Endian.
If the file is compressed, we'll need to decompress it when we open the body text later. Now, let's open the body text. The storage named BodyText contains the main content.
for entry in stream_list:
if entry[0] == "BodyText":
target_stream_path = "/".join(entry)
with ole.openstream(target_stream_path) as stream:
data = stream.read()
if props_zip: # If the file is compressed
data = zlib.decompress(data, -15)
For the reason behind specifying -15 when decompressing with zlib, please refer to this blog post.
The data consists of a series of data records. The first 4 bytes of each record specify what kind of data it is and its length.

Let's create a function to parse the record header according to the specification.
def extract_record(record_stream: bytes):
dword = int.from_bytes(record_stream, byteorder="little")
tag_id = (dword >> 0) & 0x3FF # Lower 10 bits (0b0011_1111_1111)
level = (dword >> 10) & 0x3FF # Next 10 bits
size = (dword >> 20) & 0xFFF # Next 12 bits
return tag_id, level, size
The next section shows the Tag ID where the actual text of the body is stored.
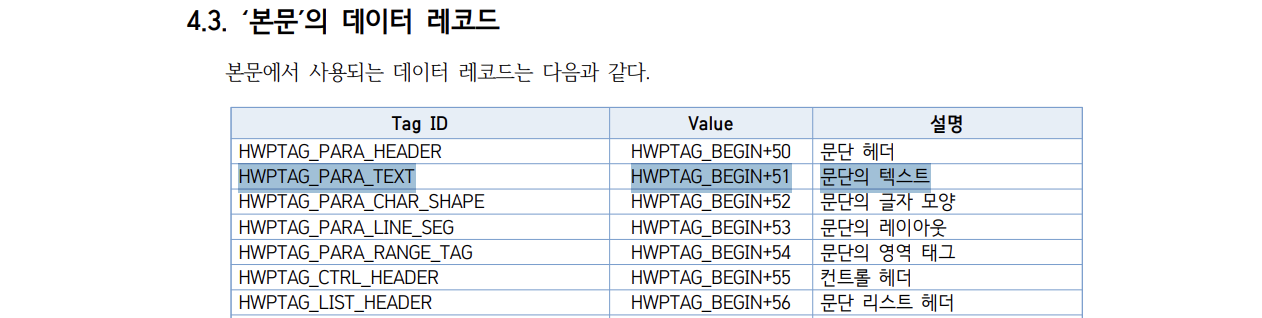
Now, let's read the file sequentially and extract only the 'paragraph text'.
HWPTAG_BEGIN = 0x010 # Specified in the docs, up to 0x00F is reserved for special purposes
HWPTAG_PARA_TEXT = HWPTAG_BEGIN + 51 # Since HWPTAG_BEGIN is 16, HWPTAG_PARA_TEXT is 67
pos = 0
while pos < len(data):
record_stream = data[pos : pos + 4]
tag_id, level, size = extract_record(record_stream)
pos += 4 # Move the current position to the data after reading the header
if tag_id == HWPTAG_PARA_TEXT:
para_stream = data[pos : pos + size]
para_stream = remove_ctrl_char(para_stream) # Control characters must be removed
para_text = para_stream.decode("utf-16")
print(para_text)
pos += size
We're almost there. If you simply read the body and convert it with utf-16, Chinese characters and special symbols will appear. Let's implement remove_ctrl_char() to delete these control characters.
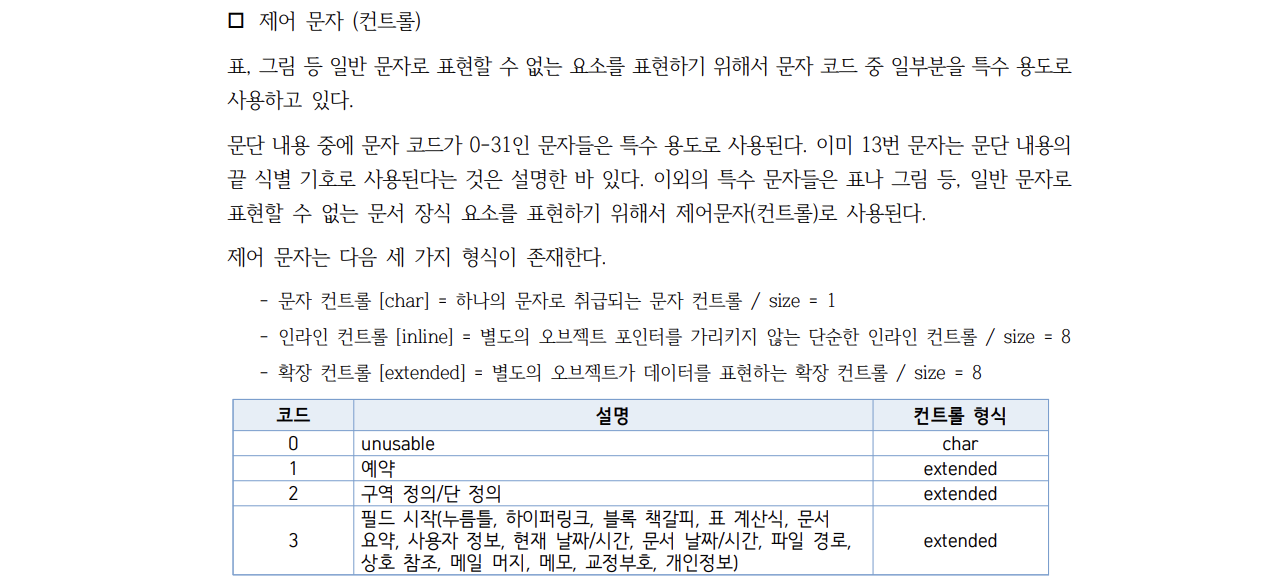
Control characters are defined as shown above. When read in 2-byte units, anything up to 31 is a control character. Among these, the ones of char type are 2 bytes, and the others are 16 bytes.
CHAR_CTRL = [0, 10, 13] + list(range(24, 32)) # List of char-type control characters
def remove_ctrl_char(para_stream: bytes):
out = b""
pos = 0
while pos < len(para_stream):
wchar_stream = para_stream[pos : pos + 2]
wchar = int.from_bytes(wchar_stream, "little") # In reality, the second byte is 0, so we only check the first
if wchar < 32:
if wchar in CHAR_CTRL:
# End of line (10) and end of paragraph (13) may need special handling
pos += 2
else:
# Need to verify that the last of the 8 DWORDs is the same as the starting control character
pos += 16
else:
out += wchar_stream
pos += 2
return out
Done! While it might not be perfect for complex documents, you can see that the text is extracted correctly.